KNIME 4.7 Python 模块相关变化
文章最新更新日期: 2023/03/04
对应《KNIME 视觉化数据分析》,P221,8.5 章节
在 KNIME 4.7 版本之后,Python 模块发生了一些变化。
其主要在于 Python 环境的配置简化、相应的节点精简以及数据交换方式的变化。
简单总结:
- 配置变简单了,但在国内环境仍然需要做一些 conda 相关的配置
- 需要通过 KNIME python 进行数据交互,比如导入
import knime.scripting.io as knio之后,通过knio.input_tables[0]获得输入端口数据;输出亦然。- 绘图变简单了,可直接支持 png、jpeg、svg、matplotlib、 seaborn 等图像的输出
配置简化
注意:如果您的系统中没有 Python 相关节点和选择,则需要自行安装 KNIME Python Integration 扩展。
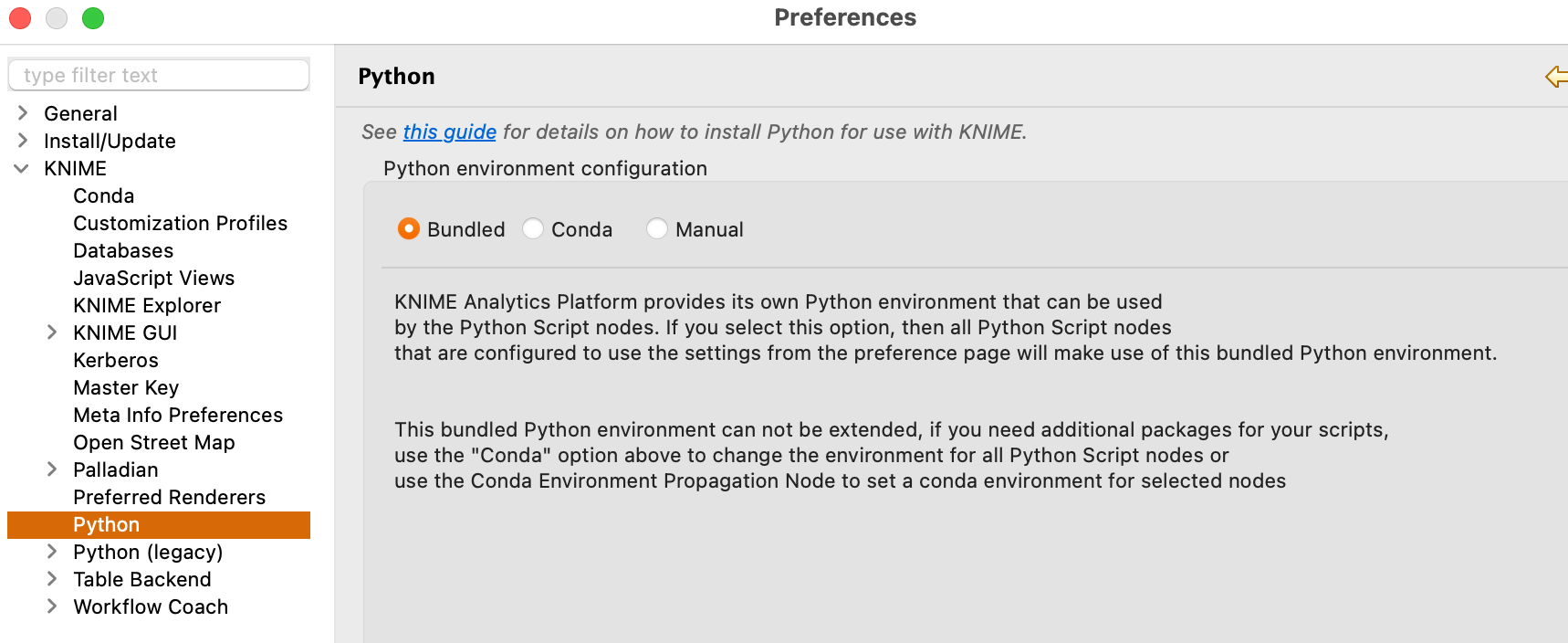
“Bundled” 配置
在之前的版本中,会有 Python 2 和 Python 3 的配置,如下图所示
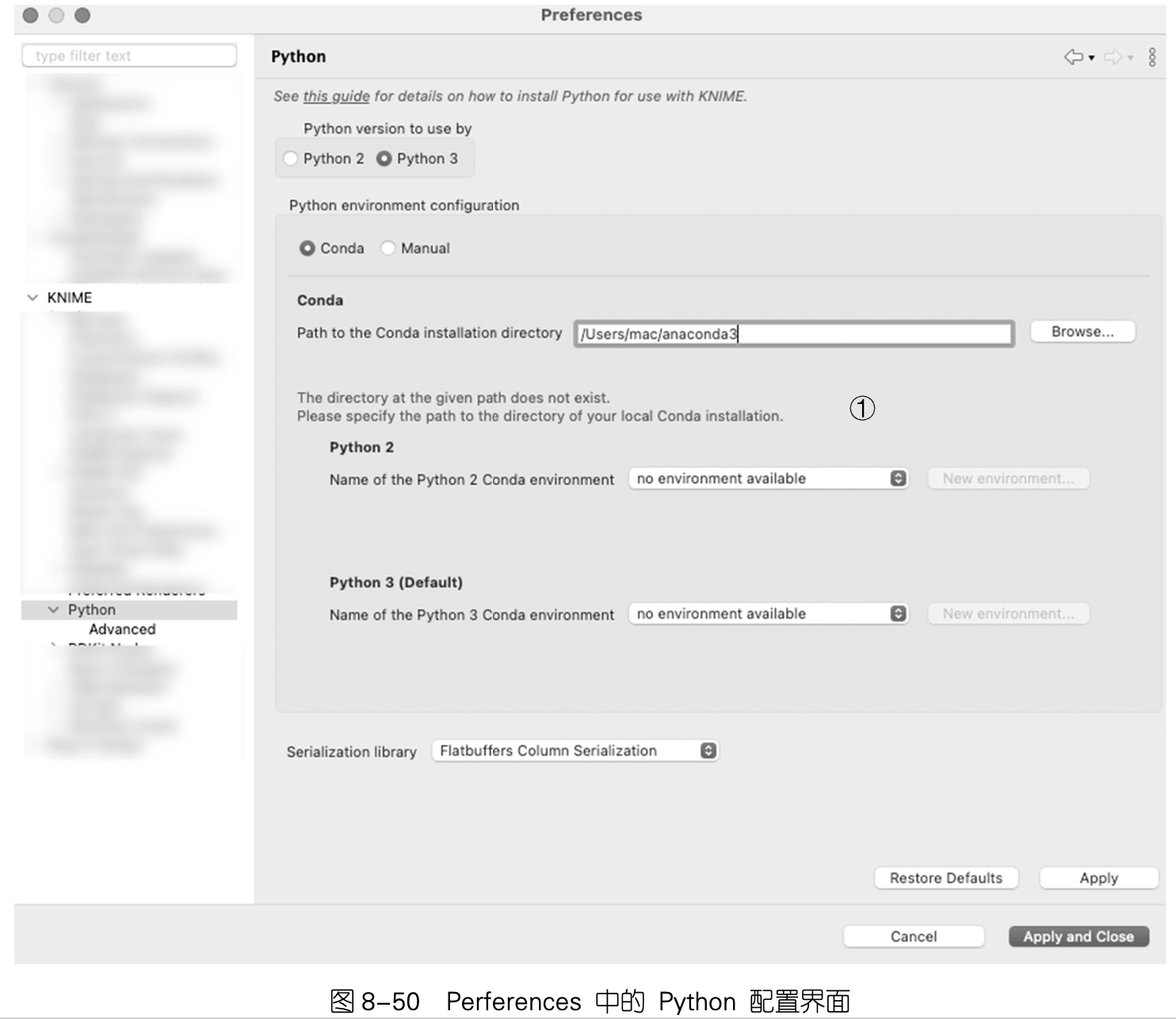
而在 KNIME 4.7 版本中,除了去掉了 Python 2 的配置之外,还附带了一个 Python 环境,即下图所说的 “Bundled”
注:如果您需要 Python 2 环境,那么您仍然需要旧版的 Python 集成插件(KNIME Python 2 Integration (legacy) 以及 KNIME Python Integration (legacy))。
Conda 配置
对于只是简单使用 Python 脚本的情况,也许 “Bundled” 就已经够用了,但是绝大部分想使用 Python 的,都想利用 Python 整个生态环境, “Bundled” 在国内的网络环境下,稍微有点勉强。仍然使用自己系统中的 conda 环境(miniconda 也可以),然后配置一个中国境内的 Python 源(比如清华、哈工大、阿里 anaconda 源和 PyPI 源),是一个比较理想的解决方案。
如果没有选用上面的 “Bundled” 环境,而是选择了 "Conda", 那么就需要先配置一下您系统中 Conda 的路径,比如在我的系统中,配置成如下形式(配置 Conda 成功后,会在页面显示 Conda Version 字样):
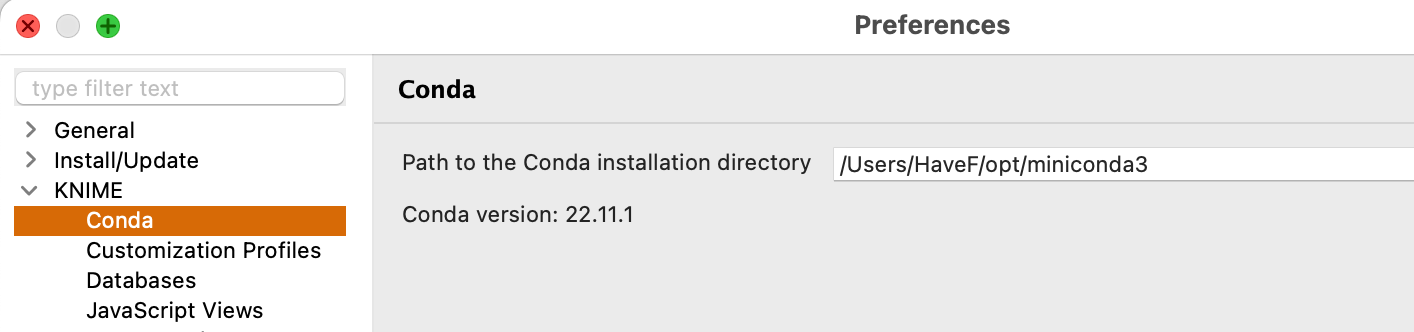
在配置好了 Conda 路径之后,再切换回 Python 的配置页面,将会看到类似如下页面:
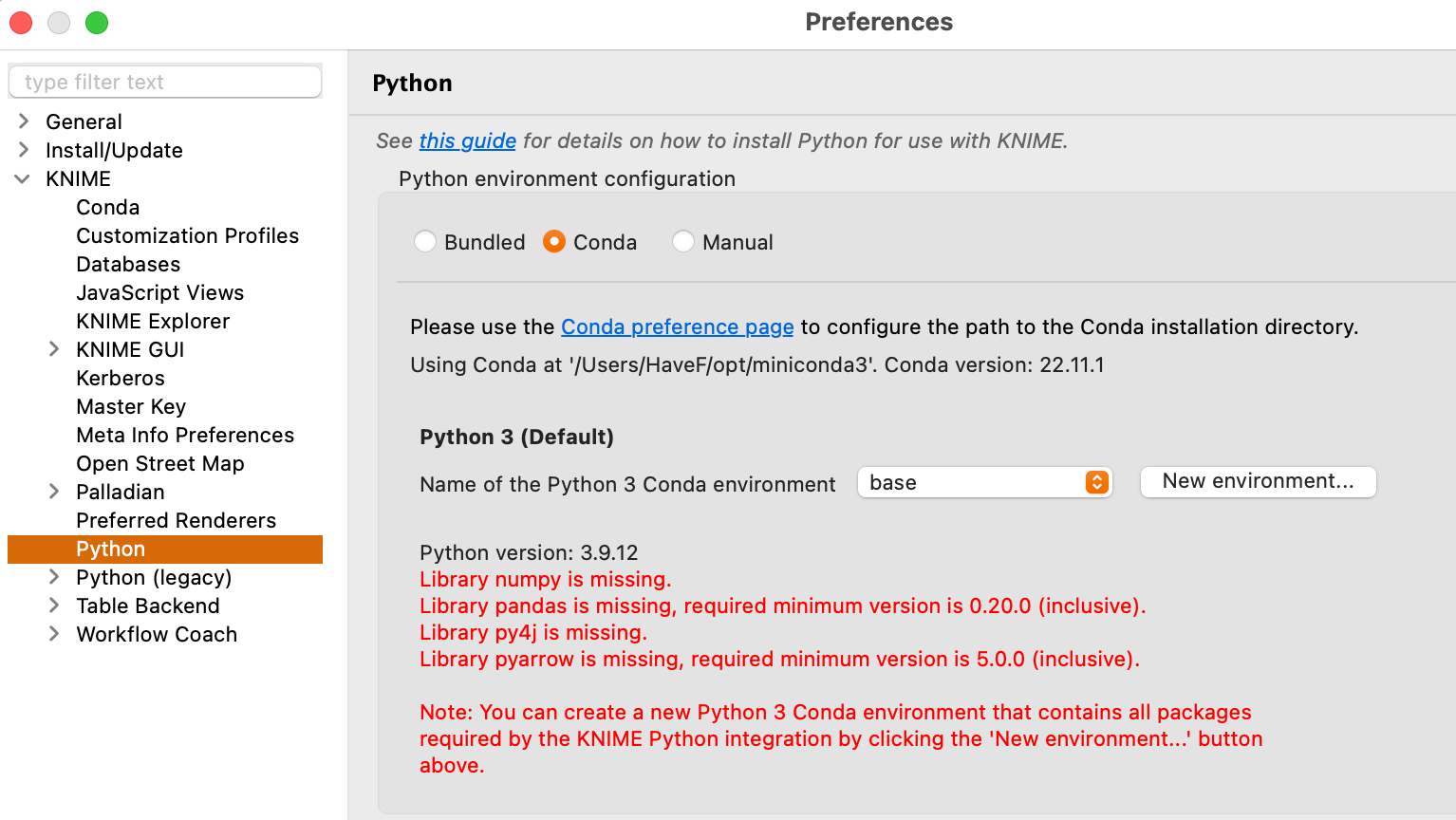
下面的红色文字是在说明,如果想使用 Python 相关的节点,那么在当前这个 “base” 环境下,还需要安装哪几个 Python 相关库。手动安装也可以,当然最简单的方式还是通过点击 "New environment..." 按钮建立一个新的、配合 KNIME 使用的 conda 环境。
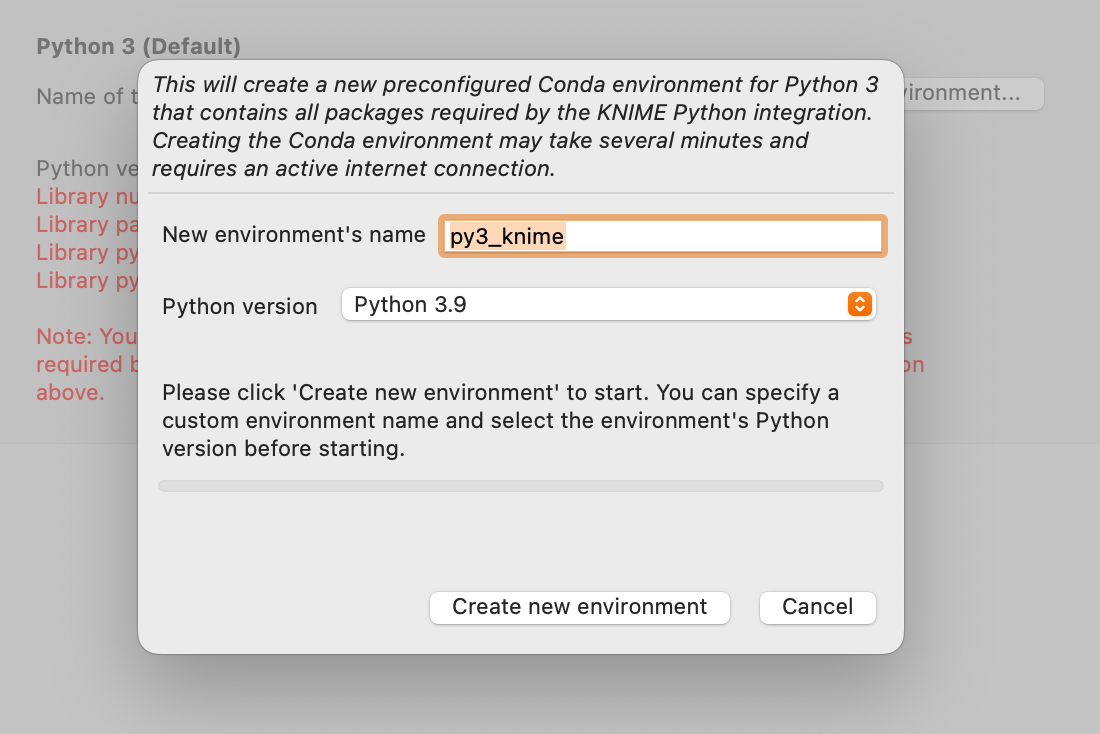
如果你之前 Python 源设置的没有问题,那么很快,这个 Conda 环境就建好了。
这个建立环境的过程也可以通过命令行来执行(出现错误时方便观察)
conda create --name py3_knime -c knime -c conda-forge knime-python-scripting=4.7 python=3.9
节点精简
在节点方面,KNIME 4.7 也做了一些精简。如下图所示:上面的两个节点就是现在的新节点,而之前版本的节点将会带有 (legacy) 字样(另外,如果您的 KNIME 是新安装的,旧 Python 扩展将不会自动安装,所以有可能看不到下面的 legacy 节点)

虽然只有两个节点,但节点的端口是可以通过点击节点图标左下角的 “...” 动态配置的,如下图所示:
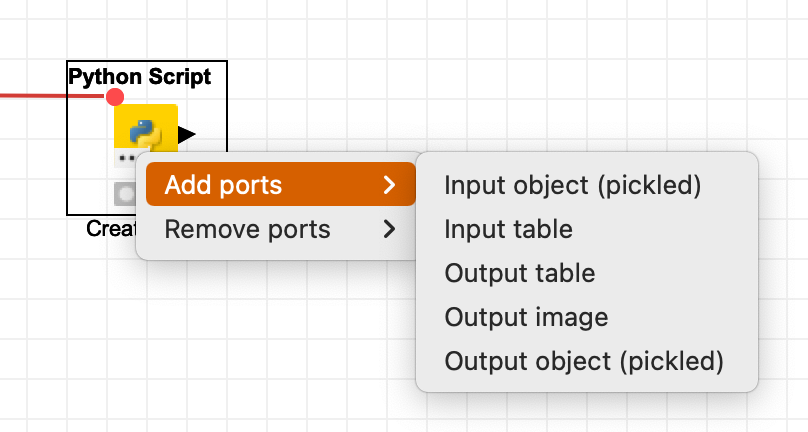
在 4.7 版本之前,如果要将 Python 空间中的表输出到 KNIME 空间,那么就需要将这个值赋给一个叫 “output_table” 的变量,这种 “硬编码” 其实是一种代码的“坏味道”。在新版本中,如果想要输出结果,需要通过 KNIME 的一个 Python 包进行赋值。比如:
import knime.scripting.io as knio
....
....
knio.output_tables[0] = knio.Table.from_pandas(output_table)
....
....
可以看出,这种方式有更多的灵活性,如果想要输出多个表到 KNIME 空间中,除了先要在节点处配置端口之外,在脚本中,只需要通过 knio.output_tables[??] 指定输出哪个端口就好了。通过 knime-python-scripting 这一层的处理,原来的 NaN、None 问题(见书 229 页)也统一了,现在全变成 KNIME 中的 ?,即缺失项。
同样,如果您想要将 KNIME 中的数据在 Python Script 节点中进行处理,那么也需要将其先转换为 Pandas 的数据帧(DataFrame)或 PyArrow Table,再利用 Python 的生态进行处理,最后再将其转换为 KNIME 相应格式即可。
df = knio.input_tables[0].to_pandas()knio.output_tables[0] = knio.Table.from_pandas(df)table = knio.input_tables[0].to_pyarrow()knio.output_tables[0] = knio.Table.from_pyarrow(table)
另外一个 Python 节点是 Python View,现在使用 figure 对象就可以直接绘图了,比以前方便一些,可直接支持 png、jpeg、svg、matplotlib、 seaborn、plotly 等图像的输出,可参见节点的 “Templates” 模版标签页进行使用。
import matplotlib.pyplot as plt
....
# Plot the histogram
fig = plt.figure()
plt.hist(np.array(values), bins=10)
# Assign the figure to the output_view variable
knio.output_view = knio.view(fig) # alternative: knio.view_matplotlib()
另外,调用环境变量的方式需要通过如下方式调用: knio.flow_variables['flow_var_name']
底层逻辑
4.7 之前的 KNIME 只是使用了 Pandas 进行一些和 Python 进行数据交换。但现在 KNIME 内部主要使用的是 Apache Arrow 这种数据格式和 Python 进行数据交换。Apache Arrow 是一种独立于语言的列式内存格式,可以在 CPU 和 GPU 等现代硬件上进行高效的分析操作。Arrow 内存格式还支持零拷贝读取,无需序列化开销,数据存取的速度会变快。
所以当我们看输入的数据类型时,我们会发现在 Python 节点中,它已经是 arrow 相关类型了(这不是 PyArrow 的数据类型,而是 KNIME 自定义的以 arrow 为基础的数据类型)
print(type(knio.input_tables[0]))
#<class 'knime._arrow._table.ArrowSourceTable'>
print(type(knio.input_tables[0]['double_column']))
#<class 'knime.api.table._TabularView'>
与 Jupyter 的交互
根据上述 4.7 版本的 KNIME 和 Python 的交互可以想象这里也会有类似的改变。但大体流程是没有变化的。 P233 页的脚本变化如下:
import knime.scripting.io as knio
import knime.scripting.jupyter as knupyter
notebook_location = knio.flow_variables['notebook_path']
# Filename of the notebook
notebook_name = 'callFromKNIME.ipynb'
# Path to the folder containing the notebook
notebook_directory = notebook_location.replace(notebook_name, "")
# Load the notebook as a Python module
my_notebook = knupyter.load_notebook(notebook_directory, notebook_name)
# Call a function 'custom_transformation' defined in the notebook
df_from_notebook = my_notebook.trans_table(knio.input_tables[0].to_pandas())
knio.output_tables[0] = knio.Table.from_pandas(df_from_notebook)
可以看到中间加入了 .to_pandas() 和 .from_pandas 的相关变换。原因就是上面所说的“底层逻辑”的变化。我们也可以在 notebook 中使用 arrow 相关库对数据进行处理,这种情况下,我们就需要将上面的 to/from pandas 相关的处理,变换成 to_pyarrow() 和 from_pyarrow() 相关的处理了。
在 Python 中调用 KNIME 的工作流
这一部分需要的 python 的 knime 库(在 pip 上),和上面的 knime-python-scripting=4.7 有所冲突,还需等待官方修正。